1. 트랜스포머 소개
본 시리즈에서는 2017년에 논문 Attention is All You Need에서 처음 제안한 모델, 트랜스포머를 소개하려고 합니다! 트랜스포머는 자연어처리를 공부하려고 한다면 필히 눈여겨보아야 할 딥러닝 모델입니다. 요즘 한창 뜨는 OpenAI의 ChatGPT는 GPT-3.5 기반으로 만들어진 모델인데, 이 GPT 시리즈도 트랜스포머 기반의 모델입니다.

트랜스포머는 위에서 언급한 논문 Attention is All You Need(2017)에서 제안된 딥러닝 모델입니다. 입력 시퀀스를 집어넣으면 모델 내부에서 처리하여 출력 시퀀스를 반환하죠. 시퀀스는 단어들이 쭉 이어진 글 비스무리한 것으로 생각하시면 됩니다. 사용자가 글을 입력하면 글로 답변하는 ChatGPT를 생각하시면 쉽습니다. 트랜스포머는 어떤 성격의 시퀀스들을 학습시키는지에 따라 굉장히 여러가지 일들을 할 수 있습니다. 예를 들어 번역을 할 수 있습니다. 번역 전의 글을 입력하면 번역된 글을 출력하도록 하는 거죠. 그 외에도 요약, 이어쓰기 등의 일들을 할 수 있습니다. 트랜스포머가 어떻게 입력 시퀀스로부터 출력 시퀀스를 생성하는지는 잠시 후 자세히 알아보겠습니다.

트랜스포머의 대세 비결 = Self-Attention!
위 그림(출처)은 컴퓨터 비전 및 자연어 처리 분야에서의 대세 모델들을 표시한 그림입니다. 그림에서 볼 수 있듯이, 트랜스포머는 제안된 후 기존에 가장 인기 있었던 딥러닝 모델인 CNN, RNN을 제치고 대세가 되었습니다. 트랜스포머를 기반으로 한 딥러닝 모델들은 각종 벤치마크에서 신기록을 경신했구요. 트랜스포머의 강점은 CNN, RNN에 비해 연산을 병렬 처리하기에 유리하다는 것입니다. 이는 트랜스포머가 Self-Attention에 완전히 의존하는 덕분입니다. 트랜스포머는 CNN에서 쓰이는 Convolution 연산 및 RNN에서 쓰이는 Recurrence 연산을 사용하지 않고 Self-Attention 연산에만 의존하는 최초의 모델이었습니다. Self-Attention 연산이 무엇인지는 다음 편에서 자세히 알아보겠습니다.
2. 트랜스포머의 훈련 방법
트랜스포머는 딥러닝 모델이므로, 미리 훈련시켜 두어야 글을 척척 생성할 수 있게 됩니다. 트랜스포머를 훈련시키려면 수많은 입력 시퀀스-출력 시퀀스 쌍들로 이루어진 훈련 데이터셋을 미리 준비해야 합니다.
훈련 과정은 다른 딥러닝 모델들과 비슷합니다. 먼저 훈련 데이터셋에 있는 입력 시퀀스를 집어넣으면 트랜스포머는 출력 시퀀스에 나타날 것 같은 단어들을 하나하나 차례대로 예측합니다. 이를 위해서는 훈련을 시작하기 전에 훈련 데이터셋에 등장하는 단어들을 미리 정리해 둔 ‘단어 집합’을 만들어두어야 합니다. ‘예측’은 단어 집합에 있는 각 단어들이 각 시점에 등장할 확률을 계산하는 것입니다.
트랜스포머가 예측을 수행하고 나면 훈련 데이터셋에 있는 ‘정답’ 출력 시퀀스와 비교하며 채점을 합니다. 미리 정해둔 손실 함수에 예측과 정답을 집어넣으면 손실 값, 그러니까 예측이 맞고 틀린 정도가 반환됩니다.
트랜스포머의 손실 함수는 = 크로스 엔트로피!
트랜스포머에서는 손실 함수로 크로스 엔트로피(Cross Entropy) 함수를 사용합니다. 크로스 엔트로피 함수식은 아래와 같습니다.
H(x)=−∑q(xi)logp(xi)
위 식에서 xi들은 단어 집합의 각 단어들을 나타냅니다. q는 xi가 정답인지 여부를 나타내는 값입니다. 현재 시점에서 xi 단어가 등장하는 것이 맞다면 1, 아니라면 0이 됩니다. p는 훈련 중인 트랜스포머 모델이 예측에서 구한, xi가 현재 시점에 등장할 확률입니다.
그렇다면 한 번 생각해봅시다. xi가 정답일 때에만 q값이 1이 되는 상황입니다. xn이 정답이라고 한다면 H=−logp(xn)와 같을 것입니다. p는 0과 1 사이의 값이므로 음수일 것이고, p가 작아질수록 H는 커질 것입니다. 모델이 정답 단어의 등장 확률을 낮게 예측할수록 손실 값이 커지겠네요. 손실함수는 이렇게 ‘오차’를 구해내는 함수입니다.
크로스 엔트로피 함수로 오차를 구하고 나면 딥러닝 모델에서 으레 그렇듯, 오차가 역전파(Backpropagation)되며 가중치 값이 업데이트하게 됩니다. 이 과정을 각 배치(Batch)에 대하여 정해진 에폭시(Epoch) 수만큼 반복하면 모델의 예측이 점점 정확해집니다.
배치? 에폭시?
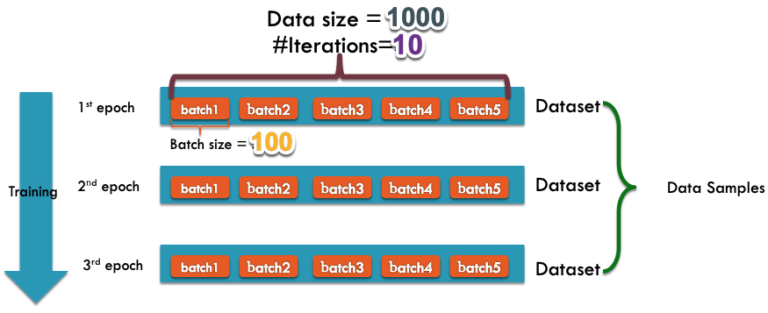
배치, 에폭시가 무엇인지 간단히 알아보겠습니다. 배치, 에폭시가 뭔지 아신다면 이 부분은 건너뛰어주세요! 모르신다면 위의 그림(출처)을 참고하면서 읽어주세요.
먼저 훈련 데이터셋 전체를 한 번씩 학습시키는 것을 하나의 에폭시라고 합니다. 만약 에폭시 수가 5라면 훈련 데이터셋에 있는 모든 입력-출력 시퀀스 쌍이 총 5번씩 모델의 학습에 사용됩니다.
다음으로 배치에 대해 알아보겠습니다. 딥러닝 모델을 학습시킬 때 가중치를 한 번 업데이트할 때마다 훈련 데이터셋 중 얼마만큼을 학습시킬지를 미리 정하여 끊어두는 경우가 많습니다. 이때 가중치를 한 번 업데이트할 때마다 사용하는 데이터셋 뭉텅이 하나하나가 하나의 배치가 됩니다. 예를 들어 배치 수를 10으로 정했다면 훈련 데이터셋을 10개의 뭉텅이로 나누어 두고 뭉텅이 하나를 학습시킬 때마다 가중치를 한 번씩 업데이트합니다. 배치 수와 에폭시 수는 고정된 값이 아니라 정하기 나름입니다.
3. 트랜스포머의 전체적인 구조
트랜스포머 = 인코더-디코더 구조!
앞서 트랜스포머는 입력 시퀀스를 집어넣으면 출력 시퀀스를 반환하는 모델이라고 했습니다. 이를 위해 트랜스포머에는 인코더(Encoder)와 디코더(Decoder) 블록이 갖추어져 있습니다. 인코더는 입력 시퀀스를 받은 후 처리하여 벡터들을 만들어내고, 디코더는 인코더가 만들어낸 벡터들로부터 출력 시퀀스를 생성합니다.
인코더와 디코더는 모두 각각 여러 개의 층(Layer)들이 쌓인 형태입니다. 층의 개수는 정하기 나름이겠지만, 위에서 이야기한 논문에서는 인코더와 디코더에 각각 6개씩의 층을 쌓았다고 합니다. 6개의 층 모두 입력을 받으면 출력을 내보내는데, 이때 이전 층의 출력이 다음 층의 입력이 됩니다. 인코더의 6개 층은 모두 가중치는 다르지만 동일하게 구성된 함수고, 디코더의 6개 층 또한 모두 가중치는 다르지만 동일하게 구성된 함수입니다. 단, 인코더의 층과 디코더의 층은 서로 다른 함수입니다.
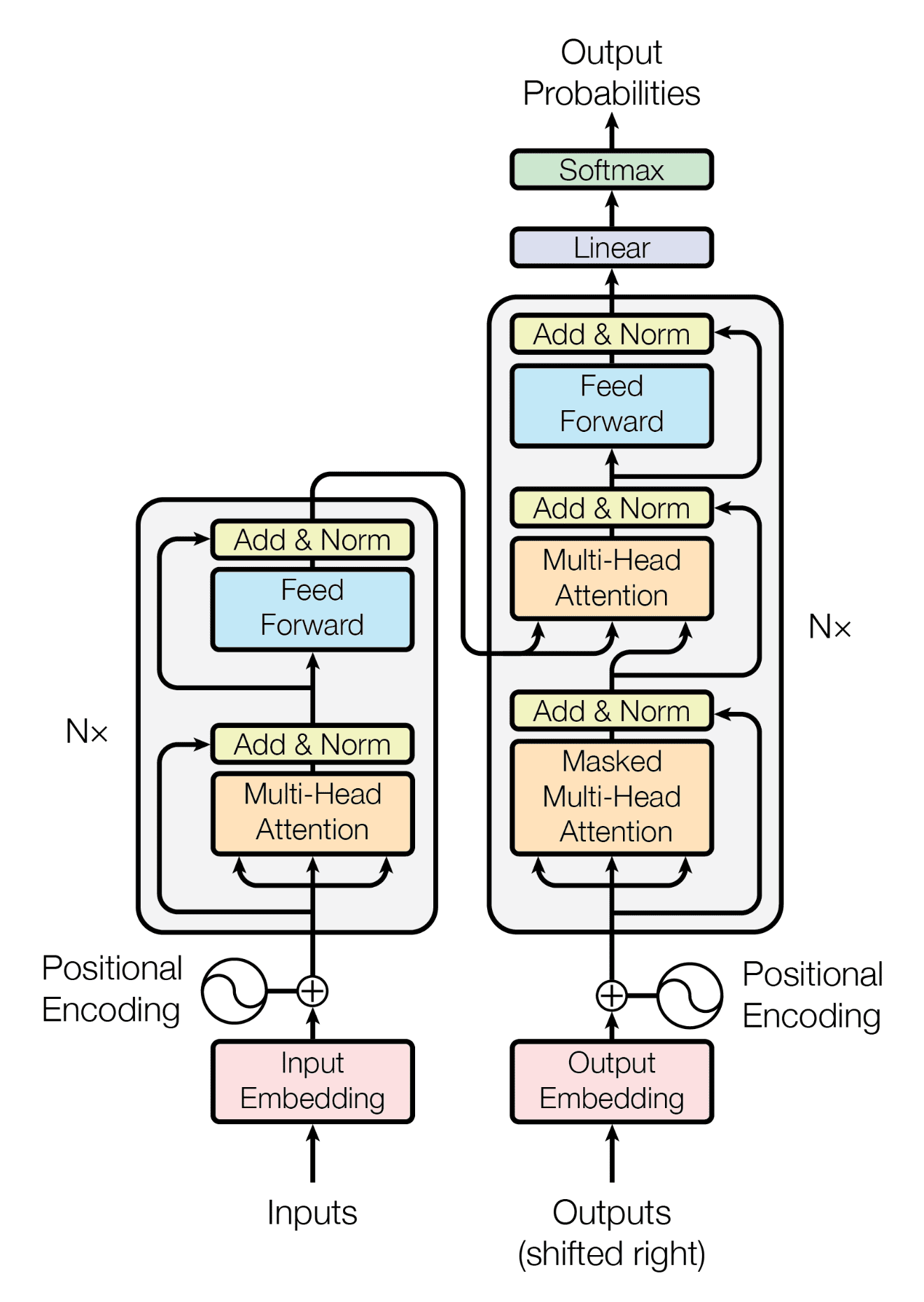
위 그림은 논문 Attention is All You Need에서 가져온 트랜스포머의 구조입니다. 그림에서 왼쪽에 있는 큰 블록이 인코더, 오른쪽에 있는 큰 블록이 디코더입니다. 인코더의 입력으로 들어가는 'Inputs'는 앞서 이야기한 입력 시퀀스와 같습니다. 인코더의 출력이 디코더에서 입력으로 사용되는 것도 그림을 통해 확인할 수 있습니다. 디코더의 입력으로 들어가는 Outputs가 무엇인지 헷갈리실 수 있는데, Outputs 위치에는 한 번에 하나씩 가장 최근에 생성된 토큰이 들어갑니다. 처음에는 문장의 시작을 나타내는 토큰이 들어가고, 이후로는 새롭게 생성된 토큰이 다시 디코더의 입력으로 들어가는 것입니다.
그림에서 확인할 수 있듯이, 인코더 및 디코더의 각 층들은 다시 여러 개의 보조층들로 나뉘어집니다. 보조층 중에서는 앞서 언급한 self-attention을 수행하는 것도 있습니다. 자세한 내용은 다음번 글에서 알아보는 것으로 하고, 오늘은 이만 여기에서 마치겠습니다.
'NLP > 트랜스포머 뜯어보기' 카테고리의 다른 글
| [트랜스포머 뜯어보기-2] Self-Attention 이해하기 (0) | 2023.03.06 |
|---|